Metadatos en Paquetes
Martín Macías / 2018-04-26
Metadatos en paquetes
El trabajo del archivo DESCRIPTION es almacenar metadatos importantes sobre su paquete. Cuando comience a escribir paquetes, generalmente usará estos metadatos para registrar qué paquetes son necesarios para ejecutar su paquete. Sin embargo, a medida que pase el tiempo y comience a compartir su paquete con otros, el archivo de metadatos se vuelve cada vez más importante porque especifica quién puede usarlo (la licencia) y con quién contactarse (¡usted!) si hay algún problema.
Cada paquete debe tener un DESCRIPTION. De hecho, es la característica definitiva de un paquete (RStudio y devtools consideran cualquier directorio que contiene DESCRIPTION como un paquete). Para comenzar, devtools::create("mypackage") agrega automáticamente un escueto archivo de descripción. Esto le permitirá comenzar a escribir el paquete sin tener que preocuparse por los metadatos hasta que lo necesite. La descripción mínima variará un poco dependiendo de su configuración, pero debería verse más o menos así:
Package: mypackage
Title: What The Package Does (one line, title case required)
Version: 0.1
Authors@R: person("First", "Last", email = "first.last@example.com",
role = c("aut", "cre"))
Description: What the package does (one paragraph)
Depends: R (>= 3.1.0)
License: What license is it under?
LazyData: true(Si está escribiendo muchos paquetes, puede establecer opciones globales mediante devtools.desc.author, devtools.desc.license, devtools.desc.suggests, y devtools.desc. Consulte package?devtools para más detalles.)
DESCRIPTION usa un formato de archivo simple llamado DCF, el formato de control de Debian. Puede ver más de la estructura en el ejemplo simple más abajo. Cada línea consiste en un nombre field y un valor, separados por dos puntos. Cuando los valores abarcan varias líneas, deben sangrarse:
Description: La descripción de un paquete suele ser larga,
abarcando varias líneas. La segunda línea y subsecuentes
deberían estar sangradas, usualmente con cuatro espacios.Este capítulo le mostrará cómo usar los campos DESCRIPTION más importantes.
Dependencias: ¿Qué necesita su paquete?
El trabajo de DESCRIPTION es enumerar los paquetes que su paquete necesita para funcionar. R tiene un amplio conjunto de formas de describir posibles dependencias. Por ejemplo, las siguientes líneas indican que su paquete necesita tanto ggvis como dplyr para funcionar:
Imports:
dplyr,
ggvisMientras que las líneas a continuación indican que, si bien su paquete puede aprovechar ggvis y dplyr, no se necesitan para que funcionen:
Suggests:
dplyr,
ggvisTanto Imports como Suggests toman una lista de nombres de paquetes separados por comas. Recomiendo poner un paquete en cada línea, y mantenerlos en orden alfabético. Eso hace que sea fácil de revisar.
Imports y Suggests difieren en su fuerza de dependencia:
Imports: los paquetes enumerados aquí deben estar presentes para que su paquete trabaje. De hecho, cada vez que su paquete sea instalado, esos paquetes, si no están presentes, serán instalados en su computadora (devtools::load_all()también verifica que los paquetes estén instalados).Agregar una dependencia de paquete aquí asegura que se instalará. Sin embargo, no significa que se adjuntará junto con su paquete (es decir,
library(x)). La mejor práctica es referirse explícitamente a funciones que usan la sintaxispackage::function(). Esto hace que sea muy fácil identificar qué funciones viven fuera de su paquete. Esto es especialmente útil cuando lea su código en el futuro.Si usa muchas funciones de otros paquetes, esto es bastante diciente. También hay una penalización de rendimiento menor asociada con
::(del orden de 5μs, entonces solo importará si llama a la función millones de veces). Aprenderá formas alternativas de llamar a funciones en otros paquetes en namespace imports.Suggests: su paquete puede usar estos paquetes, pero no los requiere. Puede usar paquetes sugeridos para conjuntos de datos de ejemplo, para ejecutar pruebas, crear viñetas, o tal vez solo hay una función que necesite el paquete.Los paquetes enumerados en
Suggetsno se instalan automáticamente junto con su paquete. Esto significa que debe verificar si el paquete está disponible antes de usarlo (userequireNamespace(x, quietly = TRUE)). Existen dos escenarios básicos:# Necesita el paquete sugerido para esta función my_fun <- function(a, b) { if (!requireNamespace("pkg", quietly = TRUE)) { stop("Paquete \"pkg\" necesario para que esta función trabaje. Por favor, instálela.", call. = FALSE) } } # Hay un método alternativo si el paquete no está disponible my_fun <- function(a, b) { if (requireNamespace("pkg", quietly = TRUE)) { pkg::f() } else { g() } }
Al desarrollar paquetes localmente, nunca necesitará usar Suggests. Cuando libere su paquete, usar Suggests es una cortesía para sus usuarios. Les permite descargar paquetes que rara vez se necesitan y les permite comenzar con su paquete lo más rápido posible.
La forma más fácil de agregar Imports y Suggests a su paquete es usar devtools::use_package(). Esto los coloca automáticamente en el lugar correcto en su DESCRIPTION, y le recuerda cómo usarlos.
devtools::use_package("dplyr") # Por defecto para importar
#> Agrega dplyr a Imports
#> Consulte las funciones con dplyr::fun()
devtools::use_package("dplyr", "Suggests")
#> Agrega dplyr a Suggests
#> Use requireNamespace("dplyr", quietly = TRUE) para probar si el
#> paquete está instalado, luego use dplyr::fun() para referirse a
#> a las funcionesVersiones
Si necesita una versión específica de un paquete, especifíquelo en paréntesis después del nombre del paquete:
Imports:
ggvis (>= 0.2),
dplyr (>= 0.3.0.1)
Suggests:
MASS (>= 7.3.0)Casi siempre debería especificar una versión mínima en lugar de una versión exacta (MASS (==7.3.0)). Como R no puede tener múltiples versiones del mismo paquete cargadas al mismo tiempo, la especificación de una dependencia exacta aumenta drásticamente las posibilidades de versiones en conflicto.
El control de las versiones es más importante cuando lanza su paquete. Por lo general, las personas no tienen exactamente las mismas versiones de paquetes instalados que usted. Si alguien tiene un paquete anterior que no tiene una función que su paquete necesita, recibirá un mensaje de error inútil. Sin embargo, si proporciona el número de versión, recibirán un mensaje de error que les dice exactamente cuál es el problema: un paquete desactualizado.
En general, siempre es mejor especificar la versión y ser conservador sobre qué versión requerir. A menos que sepa lo contrario, siempre solicite una versión mayor o igual que la versión que esté utilizando actualmente.
Otras dependencias
Hay otros tres campos que le permiten expresar dependencias más especializadas:
Depends: antes del despliegue de espacios de nombres en R 2.14.0,Dependsera la única forma de “depender” de otro paquete. Ahora, a pesar del nombre, usted casi siempre debería usarImports, noDepends. Aprenderá por qué, y cuándo todavía seguir usandoDepends, en namespaces.También puede usar
Dependspara requerir una versión específica de R, por ej.Depends: R (>= 3.0.1). Al igual que con los paquetes, es una buena idea ir sobre seguro y requerir una versión mayor o igual que la versión que está usando actualmente.devtools::create()hará esto por usted.En R 3.1.1 y anteriores también necesitará usar
Depends: methodssi usa S4. Este error se soluciona en R 3.2.0, por lo que los métodos pueden volverImportsa donde pertenecen.LinkingTo: los paquetes enumerados aquí dependen del código C o C ++ en otro paquete. Aprenderá más sobreLinkingToen Compiled code.Enhances: los paquetes enumerados aquí son “mejorados” por su paquete. Típicamente, esto significa que usted proporciona métodos para las clases definidas en otro paquete (una especie de idea contraria a ‘Suggests’). Pero es difícil definir lo que eso significa, así que no recomiendo usarEnhances.
También puede enumerar las cosas que su paquete necesita fuera de R en el campo SystemRequirements. Pero esto es solo un campo de texto plano y no se verifica automáticamente. Piense en ello como una referencia rápida; también deberá incluir requisitos detallados del sistema (y cómo instalarlos) en su archivo README.
Título y descripción: ¿Qué hace su paquete?
Los campos de título y descripción describen lo que hace el paquete. Se diferencian solo en longitud:
Titlees una descripción de una línea del paquete, y a menudo se muestra en listado de paquetes. Debe ser texto sin formato (sin marcado), en mayúscula como un título, y NO terminar en un punto. Que sea breve: las listas a menudo truncan el título a 65 caracteres.Descriptiones más detallado que el título. Puede usar oraciones múltiples pero está limitado a un párrafo. Si su descripción abarca múltiples líneas (¡y debería!), cada línea no debe tener más de 80 caracteres de ancho. Sangra las líneas siguientes con 4 espacios.
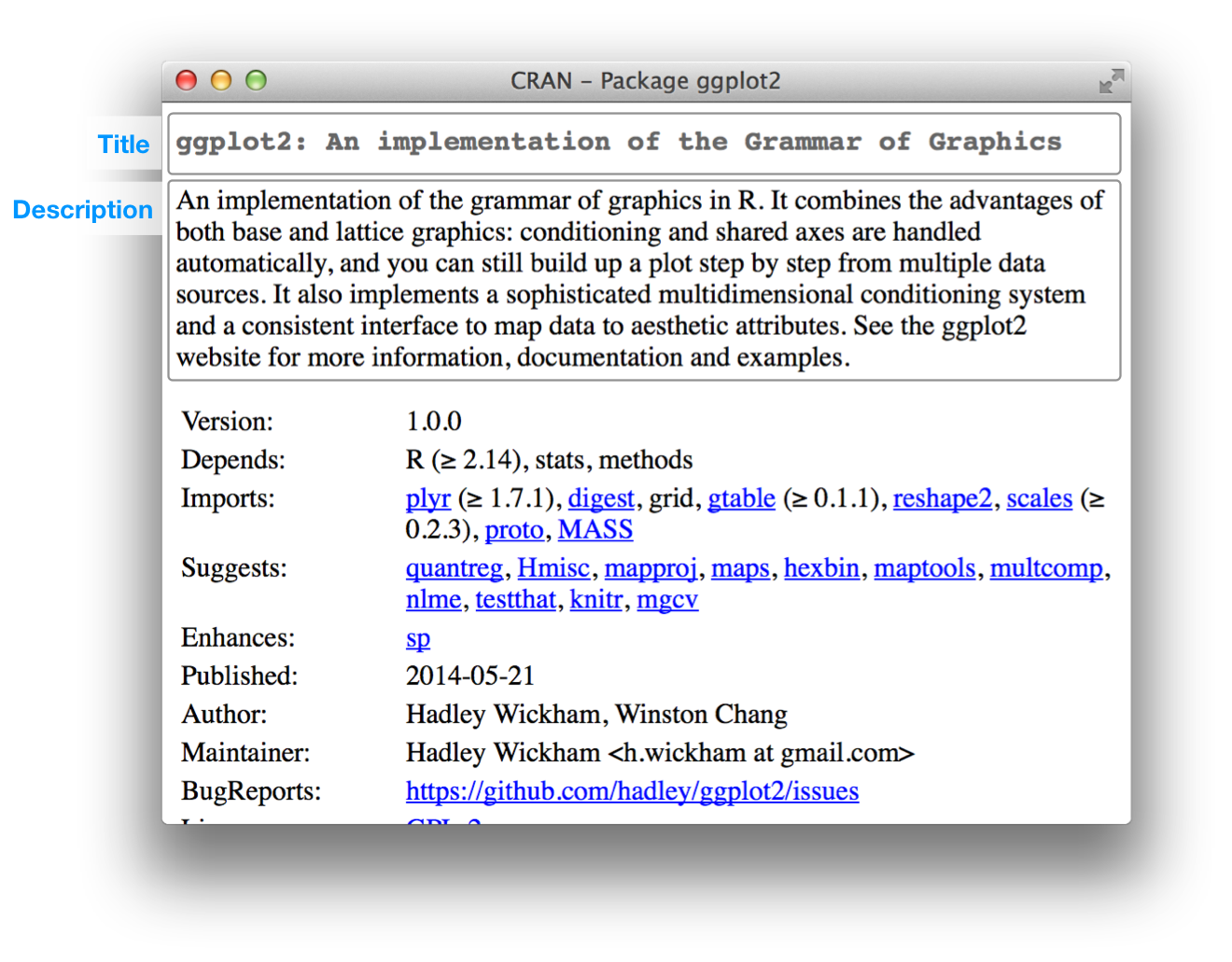
El Title y Description para ggplot2 son:
Title: An implementation of the Grammar of Graphics
Description: An implementation of the grammar of graphics in R. It combines
the advantages of both base and lattice graphics: conditioning and shared
axes are handled automatically, and you can still build up a plot step by
step from multiple data sources. It also implements a sophisticated
multidimensional conditioning system and a consistent interface to map
data to aesthetic attributes. See the ggplot2 website for more
information, documentation and examples.Un buen título y descripción son importantes, especialmente si planea lanzar su paquete al CRAN porque aparecen en la página de descarga del CRAN de la siguiente manera:
Debido a que Description solo le da una pequeña cantidad de espacio para describir lo que hace su paquete, también recomiendo incluir un archivo README.md que entra en mucha más profundidad y muestra algunos ejemplos. Aprenderá sobre eso en README.md.
Autor: ¿Quién es usted?
Para identificar el autor del paquete y con quién contactar si algo sale mal, use el campo Authors@R. Este campo es inusual porque contiene código en R ejecutable en lugar de texto sin formato. Aquí hay un ejemplo:
Authors@R: person("Hadley", "Wickham", email = "hadley@rstudio.com",
role = c("aut", "cre"))person("Hadley", "Wickham", email = "hadley@rstudio.com",
role = c("aut", "cre"))## [1] "Hadley Wickham <hadley@rstudio.com> [aut, cre]"Este comando dice que tanto el autor (aut) como el mantenedor (cre) es Hadley Wickham, y que su dirección de correo electrónico es hadley@rstudio.com. La función person() tiene cuatro argumentos principales:
El nombre, especificado por los primeros dos argumentos,
givenyfamily(estos normalmente se suministran por posición, no por nombre). En las culturas inglesas,given(primer nombre) viene antes defamily(apellido). En muchas culturas, esta convención no se sostiene.La dirección de
email.Un código de tres letras que especifica el
role. Hay cuatro roles importantes:cre: el creador o mantenedor, la persona a la que debe molestar si tiene problemas.aut: autores, aquellos que han hecho contribuciones significativas al paquete.ctb: colaboradores, aquellos que han hecho contribuciones más pequeñas, como parches.cph: titular de los derechos de autor. Esto se usa si el copyright está en manos de alguien que no sea el autor, generalmente una empresa (es decir, el empleador del autor).
(La lista completa de roles es extremadamente completa. Si su paquete tiene un leñador (“wdc”), letrista (“lyr”) o diseñador de vestuario (“cst”), descanse cómodamente pues puede describir correctamente su papel en la creación de su paquete.)
Si necesita agregar más aclaraciones, también puede usar el argumento comment y proporcionar la información deseada en texto sin formato.
Puede enumerar varios autores con c():
Authors@R: c(
person("Hadley", "Wickham", email = "hadley@rstudio.com", role = "cre"),
person("Winston", "Chang", email = "winston@rstudio.com", role = "aut"))Alternativamente, puede hacer esto concretamente usando as.person():
Authors@R: as.person(c(
"Hadley Wickham <hadley@rstudio.com> [aut, cre]",
"Winston Chang <winston@rstudio.com> [aut]"
))(Esto solo funciona bien para nombres con solo un nombre y apellido).
Cada paquete debe tener al menos un autor (aut) y un mantenedor (cre) (pueden ser la misma persona). El creador debe tener una dirección de correo electrónico. Estos campos se utilizan para generar la cita básica para el paquete (por ejemplo, citation("pkgname")). Solo las personas nombradas como autores se incluirán en la cita autogenerada. Hay algunos detalles adicionales si incluye el código que otras personas han escrito. Como esto normalmente ocurre cuando está empaquetando una librería en C, se discute en código compilado.
Además de su dirección de correo electrónico, también es una buena idea enumerar otros recursos disponibles para obtener ayuda. Puede enumerar las URL en URL. Múltiples URL se separan con una coma. BugReports es la URL donde se deben enviar los informes de errores. Por ejemplo, knitr tiene:
URL: http://yihui.name/knitr/
BugReports: https://github.com/yihui/knitr/issuesTambién puede usar campos separados Maintainer y Author. Prefiero no usar estos campos porque Authors@R ofrece metadatos más ricos.
En el CRAN
Lo más importante que debe tener en cuenta es que su dirección de correo electrónico (es decir, la dirección de cre) es la dirección que utilizará CRAN para contactarlo con respecto a su paquete. Por lo tanto, asegúrese de utilizar una dirección de correo electrónico que probablemente esté disponible por un tiempo. Además, debido a que esta dirección se utilizará para envíos automatizados, las políticas de CRAN requieren que sea para una sola persona (no una lista de correo) y que no requiera ninguna confirmación ni use ningún filtro.
License: ¿Quién puede usar su paquete?
El campo License puede ser una abreviatura estándar para una licencia de fuente abierta, como GPL-2 o BSD, o un puntero a un archivo que contiene más información, file LICENSE. La licencia solo es importante si planea liberar su paquete. Si no lo hace, puede ignorar esta sección. Si quiere dejar en claro que su paquete no es de código abierto, use License: file LICENSE y luego cree un archivo llamado LICENSE, que contenga, por ejemplo:
Proprietary
Do not distribute outside of Widgets Incorporated.MIT (muy similar a las licencias BSD 2 y 3). Esta es una licencia simple y permisiva. Permite a las personas usar y distribuir libremente su código sujeto a una sola restricción: la licencia siempre debe ser distribuida con el código.
La licencia de MIT es una “plantilla”, por lo que si la usa, necesita
License: MIT + file LICENSE, y un archivoLICENSEque se ve así:YEAR: <Año o años en los que se han realizado cambios> COPYRIGHT HOLDER: <Nombre del titular de los derechos de autor>GPL-2 o GPL-3. Estas son licencias de “copia izquierda”. Esto significa que cualquiera que distribuya su código en un paquete debe licenciar todo el paquete de una manera compatible con GPL. Además, cualquiera que distribuya versiones modificadas de su código (trabajos derivados) también debe hacer que el código fuente esté disponible. GPL-3 es un poco más estricto que GPL-2, cerrando algunas lagunas más antiguas.
CC0. Renuncia a todos sus derechos sobre el código y los datos para que pueda ser libremente utilizado por cualquier persona para cualquier propósito. Esto a veces se llama ponerlo en el dominio público, un término que no está bien definido ni tiene sentido en todos los países.
Esta licencia es la más adecuada para paquetes de datos. Los datos, al menos en los Estados Unidos no son susceptibles a derechos de autor, por lo que realmente no está renunciando a nada. Esta licencia solo aclara este punto.
Si desea obtener más información sobre otras licencias comunes: Github choosealicense.com es un buen lugar para comenzar. Otro buen recurso es https://tldrlegal.com/, que explica las partes más importantes de cada licencia. Si usa una licencia distinta a las tres que sugiero, asegúrese de consultar la sección “Escribir extensiones en R” en licencias.
Si su paquete incluye un código que no escribió, debe asegurarse de que cumpla con su licencia. Como esto ocurre con mayor frecuencia cuando se incluye el código fuente C, se analiza con más detalle en código compilado.
En el CRAN
Si desea liberar su paquete en el CRAN, debe elegir una licencia estándar. De lo contrario, es difícil para CRAN determinar si es legal distribuir su paquete o no. Puede encontrar una lista completa de licencias que CRAN considera válidas en https://svn.r-project.org/R/trunk/share/licenses/license.db.
Versión
Formalmente, una versión de un paquete en R es una secuencia de al menos dos enteros separados por . o -. Por ejemplo, 1.0 y 0.9.1-10 son versiones válidas, pero 1 o 1.0-devel no lo son. Puede analizar un número de versión con numeric_version.
numeric_version("1.9") == numeric_version("1.9.0")## [1] TRUEnumeric_version("1.9.0") < numeric_version("1.10.0")## [1] TRUEPor ejemplo, un paquete puede tener una versión 1.9. R considera que este número de versión es igual a 1.9.0, menor que la versión 1.9.2, y estas dos son, a su vez, menores que la versión 1.10 (que es la versión “uno punto diez”, no “uno punto uno cero”). R usa números de versión para determinar si se satisfacen las dependencias del paquete. Un paquete podría, por ejemplo, importar el paquete devtools (>= 1.9.2), en cuyo caso la versión 1.9 o 1.9.0 no funcionaría.
El número de versión de su paquete aumenta con las versiones posteriores de un paquete, pero es más que un contador incremental: la forma en que el número cambia con cada versión puede transmitir información sobre qué tipo de cambios hay en el paquete.
No recomiendo aprovechar al máximo la flexibilidad de R. En cambio, siempre use . para separar los números de versión.
Un número de versión publicado consta de tres números,
<principal>.<menor>.<parche>. Para la versión número 1.9.2, 1 es el número principal, 9 es el número menor, y 2 es el número de parche. Nunca use versiones como1.0, en cambio siempre deletree los tres componentes,1.0.0Un paquete en desarrollo tiene un cuarto componente: la versión de desarrollo. Esto debería comenzar en 9000. Por ejemplo, la primera versión del paquete debería ser
0.0.0.9000. Hay dos razones para esta recomendación: primero, hace que sea más fácil ver si un paquete se lanzó o está en desarrollo, y el uso del cuarto lugar significa que no está limitado a lo que la próxima versión será.0.0.1,0.1.0y1.0.0son todos mayores que0.0.0.9000.Incremente la versión de desarrollo, e.g. de
9000a9001si agregó una característica importante que otro paquete de desarrollo de la que dependa.Si está utilizando svn, en lugar de usar el
9000arbitrario, puede incrustar el identificador de revisión secuencial.
Este consejo aquí está inspirado en parte por la Versión semántica y por X.Org esquemas de control de versiones. Léalos si desea conocer más sobre los estándares de control de versiones utilizados por muchos proyectos de código abierto.
Volveremos a los números de versión en el contexto de la liberación de su paquete, seleccionando un número de versión. Por ahora, solo recuerde que la primera versión de su paquete debería ser 0.0.0.9000.
Otros componentes
Algunos otros campos se describen en otra parte del libro de Wickham:
Collatecontrola el orden en que se obtienen los archivos en R. Solo esto importa si su código tiene efectos secundarios; más comúnmente porque está usando S4. Esto se describe con más detalle en documentar S4.LazyDatahace que sea más fácil acceder a los datos en su paquete. Porque es tan importante, está incluido en la descripción mínima creada por devtools. Esto se describe con más detalle en datos externos.
En realidad, hay muchos otros campos raros, si es que los usa alguna vez. Se puede encontrar una lista completa en la sección “The DESCRIPTION file” del Manual de extensiones de R. También puede crear sus propios campos para agregar metadatos adicionales. Las únicas restricciones son que no debe usar nombres existentes y que, si planea enviarlo al CRAN, los nombres que use deben ser palabras en inglés válidas (por lo que no se generará una NOTE de revisión ortográfica).